Map Reduce
This paper talks about Map Reduce a programming paradigm by Google. Map Reduce is one of the most important distributed systems paper in the last few years. The authors Sanjay Ghemawat and Jefferey Dean are also present in other important systems paper of Google such as BigTable, GFS and TensorFlow.
Motivation
Google in 2003 was the largest and most popular Search engines and had workloads which involve large datasets. They had many such workloads every day. Doing all of them on a single server would be very ineffecient and hard to scale with their size. They also needed a general purpose framework to do this as some of the engineers who work on the Search algorithm would not need to waste time to write networking and scheduling code for each of their jobs.
What is Map Reduce
- Programming model
- Users specify map which generates an intermediate set of key value pairs after processing.
- Users also specify a reduce function which combine the intermediate output of map.
- Easily parallelizable
- Many real world tasks can be modeled this way.
- Abstracts details like Automatic parallelization and distribution, Fault tolerance, IO Scheduling etc.
Programming Model
Their programming model was inspired by map and reduce functions in functional
programming languages.
Map does a computation over a range of tuples and emits the result to the
reduce with a pariticular key.
Reduce would pick up all the values for a particular key and run a user defined
reduction over this range of values and return the output.
Implementation
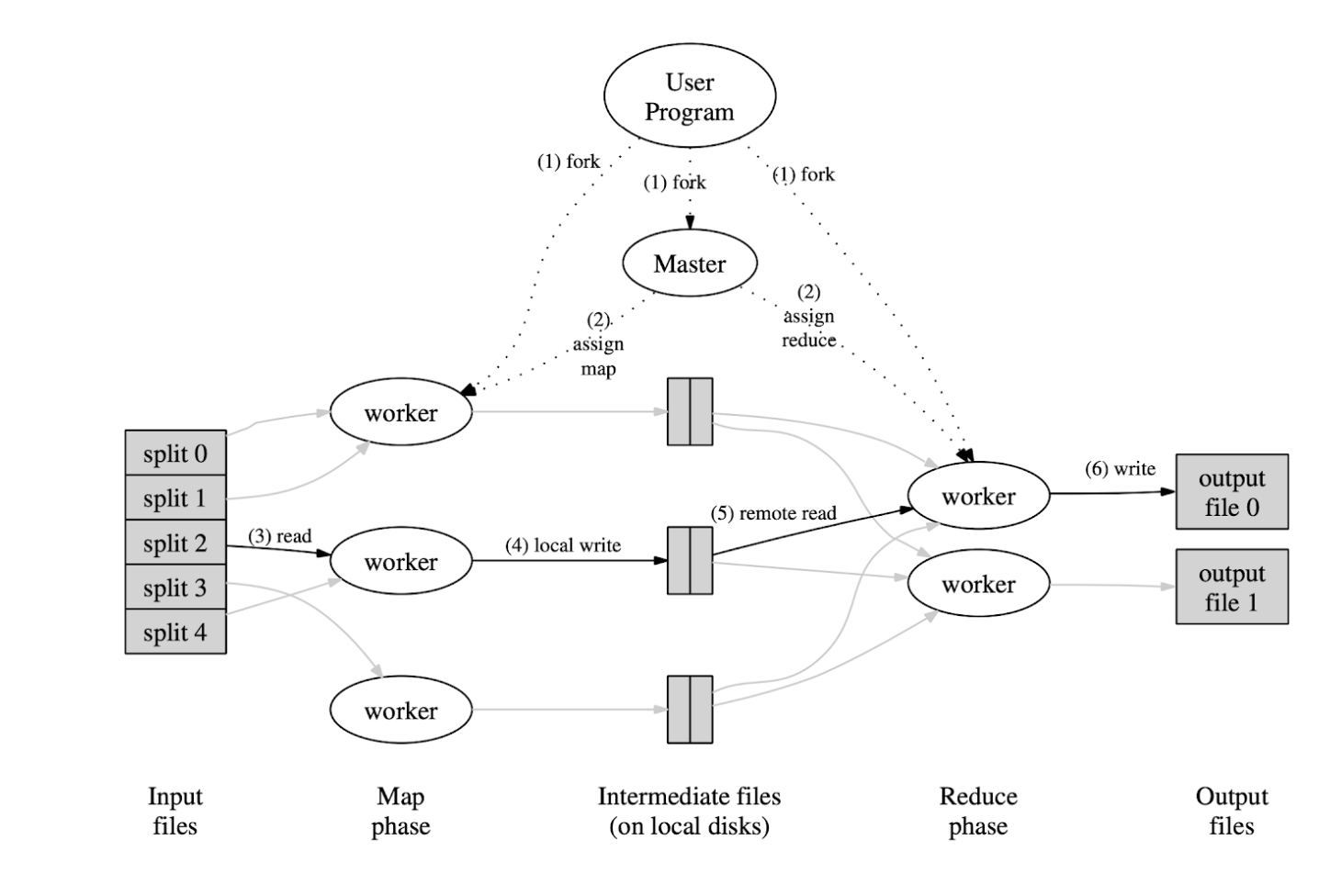
Map reduce library in the user program first splits the input files into M peices and starts up M copies of the program called workers. One copy of the program acts as the master. There are M map tasks and R reduce tasks
During the map phase , Each worker M takes up its input split reads input data and runs the map function on it. The intermediate key value pairs are buffered in memory. Periodically write key-value pairs to R regions
During the reduce phase, Reduce worked notified by master reads data via RPC. For each key it passes intermediate data through reduce function. Writes to output file and returns control to user program.
The master worker stores state of every Map and reduce task (IDLE,in-progress, completed). It also stores Identity of workers and Information regarding input and output files Map Reduce aims to provide sequential execution semantics.
Fault Tolerance
Worker Failures:
- map task reset to (idle) and scheduled on a different worker.
- Reducers notified. Tasks have to be restarted completely.
Master Failures: - Master periodically checkpoints its data structures on failure
- new master can start from last checkpoint.
Impact
The Map Reduce paper had a huge impact on the entire software industry, there was a switch from specialized supercomputers and MPI based interfaces to commodity hardware clusters in the industry. This also made writing distributed tasks easier as most of the inner workings are nicely abstracted away. At Google Map Reduce is still heavily used for a lot of its core components.
Hadoop
Hadoop is an open source version of Map Reduce originally developed by Yahoo. Hadoop is used by hundreds of companies today and is supported by Hadoop companies which provide specialized distributions