Scaling a file system to many cores using an operation log
This paper describes ScaleFS, a file system centered around the Scalable Commutativity Rule. An important contribution of this paper is to completely decouple the in-memory file system from the on-disk file system in order to scale out in the presence of multiple cores. File systems like Linux’s ext4 suffer from the problem that two commutative operations on the same directory contend for cache lines thereby directly impacting the scalability in multi-core systems.
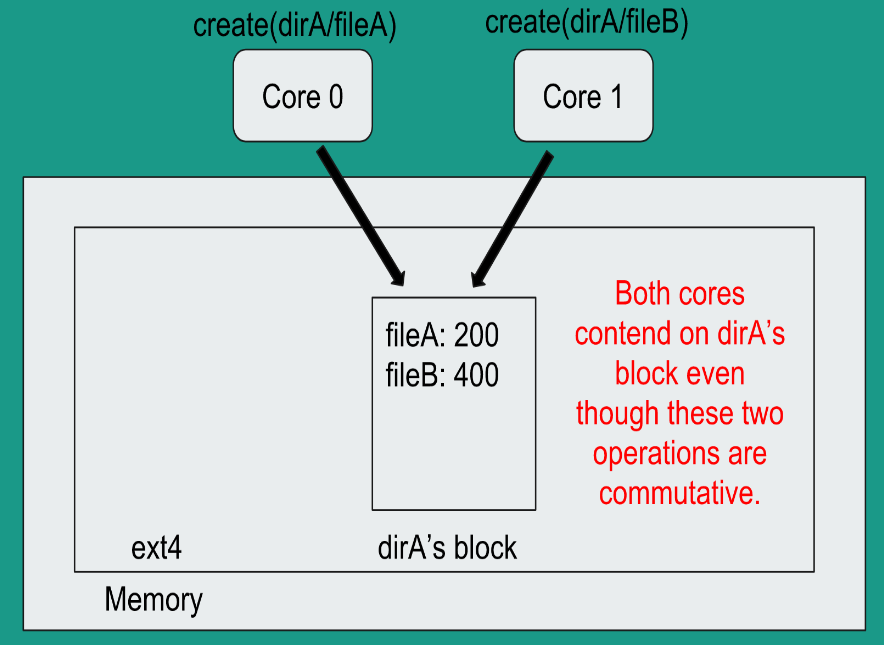
ScaleFS solves this problem by separating the in-memory data structures from the on-disk data structures with an operation log serving as a bridge between the two.
System overview
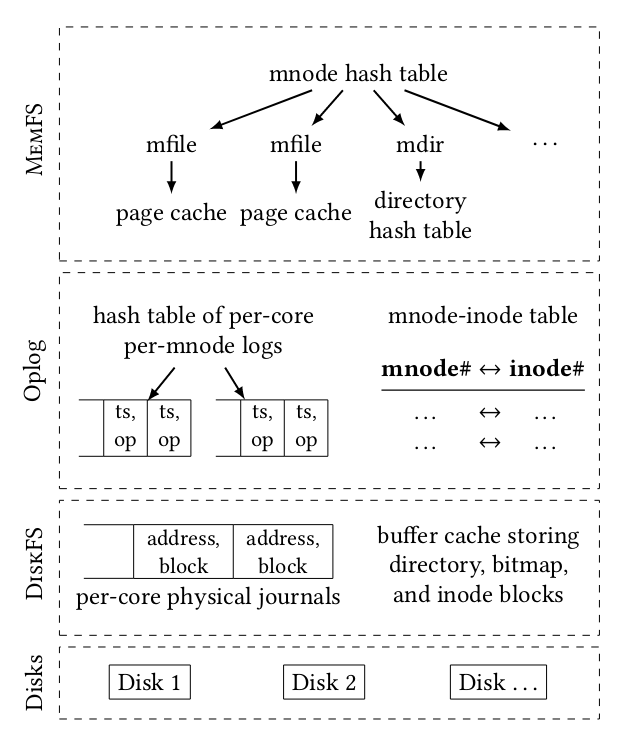
MemFS
MemFS contains a concurrent hash table with the key being an mnode (similar to inode except a file may be assigned a new mnode number after a reboot). Each mnode points to either a mfile which is a radix array of file’s pages or an mdir which is another concurrent hash table with the file name as the key and mnode of the file as the value. This hashtable essentially allows ScaleFS to avoid taking a lock over the entire directory and instead take a lock on only the file on which the operation is being performed.
Oplog
Logs are maintained in a per-core per-mnode hashtable. Only the directory operations are logged along with the timestamp of the operation. There is also an mnode-inode table which assists when the in-memory data structures are to be read/written to the disk. These logs are sorted by timestamp when flushing to the disk.
DiskFS
DiskFS maintains a set of per-core physical journals which are replayed in the event of a crash. It also maintains a buffer cache which stores directory, bitmap and inode blocks.
Given the design of ScaleFS, commutative operations from different cores usually don’t cause conflicts except in very few cases. ScalesFS also distributes each per-core journal to a subset of disks in order to scale in the presence of multiple disks whereas ext4 issues a barrier across all disks.
Comments
- Is this approach practical for workloads which compose of small files given the significant memory overhead?
- What are the security implications of having an Oplog which logs all the operations?
Get the presentation here.
Reference
Scaling a file system to many cores using an operation log by Srivatsa S. Bhat, Rasha Eqbal, Austin T. Clements, M. Frans Kaashoek, Nickolai Zeldovich